


The Customization Challenge
- A healthcare system needs LLMs that understand specific treatment protocols and clinical documentation
- A financial institution needs models that accurately interpret proprietary risk assessment methodologies
- A sales organization needs LLMs that know detailed product specifications and competitive positioning
- A government agency needs models that understand classification taxonomies and regulatory frameworks
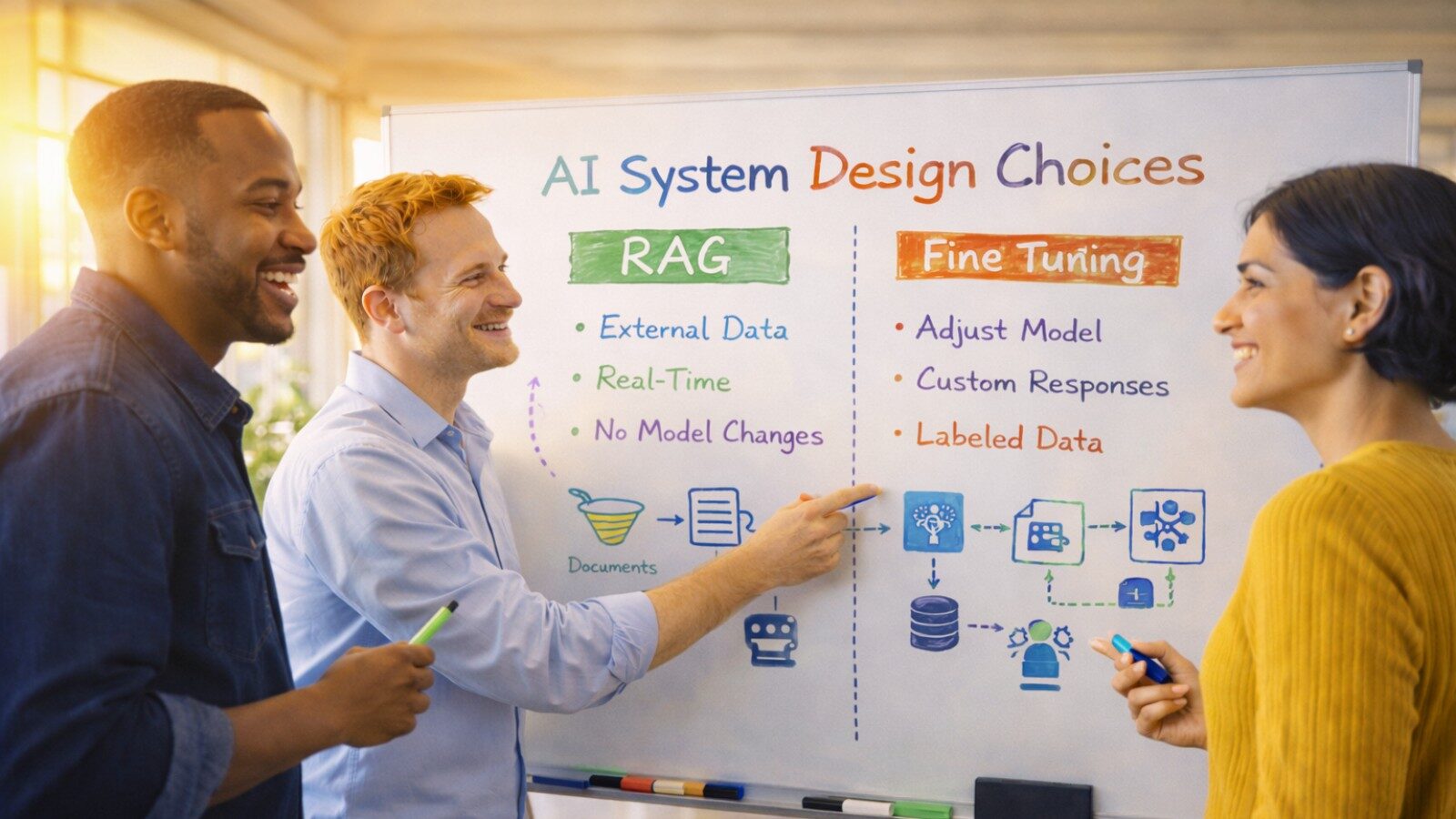
Two primary approaches have emerged for bridging this knowledge gap: Retrieval-Augmented Generation (RAG) and fine-tuning. Understanding when to use each, or how to combine them, is critical for building effective enterprise AI systems.
Out-of-the-box large language models like GPT-4, Claude, and Llama possess impressive general knowledge and reasoning capabilities. However, enterprise applications require domain-specific knowledge that foundation models don’t inherently possess:
Understanding RAG:
Retrieval-Augmented Generation
How RAG Works
RAG systems don’t modify the underlying language model. Instead, they augment the model’s context with relevant information retrieved from external knowledge sources at inference time.
The process follows a consistent pattern:
- Document Processing: Break domain-specific documents into semantically meaningful chunks
- Embedding Generation: Convert text chunks into dense vector representations
- Vector Storage: Store embeddings in a vector database (Chroma, Pinecone, Azure AI Search)
- Query Processing: Convert user queries into embeddings using the same model
- Similarity Search: Retrieve the most relevant document chunks based on vector similarity
- Context Augmentation: Inject retrieved content into the LLM prompt
- Response Generation: LLM generates a response based on augmented context
RAG in Production:
Healthcare Knowledge Assistant
Consider the HIPAA-compliant medical knowledge assistant we deployed for a specialty healthcare practice. The system needed to answer patient questions using 2,500+ clinical documents while maintaining the authentic voice of the practice’s physicians.
The RAG architecture included:
- BioBERT embeddings trained on biomedical literature, capturing clinical terminology that general-purpose embeddings miss
- Semantic chunking that preserved medical context (250-500 tokens per chunk with 50-token overlap)
- Hybrid search combining vector similarity with keyword matching for medical terms
- Azure AI Search providing HIPAA-compliant vector storage
- GPT-4 for response generation with retrieved context
The system achieved 60% reduction in routine consultation volume without fine-tuning the underlying model. Why did RAG work so well here?
- Knowledge freshness: Clinical protocols update regularly; RAG allows immediate knowledge updates without model retraining
- Transparency: Retrieved documents provide citations for medical claims
- Compliance: Data remains in HIPAA-compliant storage rather than encoded in model weights
- Cost efficiency: No expensive model training required
RAG Strengths
- Dynamic knowledge updates: Add or remove documents without model retraining
- Transparency and citations: Users can verify information against source documents
- Lower computational cost: No GPU-intensive training required
- Easier debugging: Poor responses often trace to retrieval quality rather than model behavior
- Data privacy: Sensitive information remains in external storage, not model weights
- Multi-modal knowledge: Can retrieve from structured databases, documents, images
RAG Limitations
- Context window constraints: Limited by model’s maximum context length
- Retrieval quality dependency: Poor chunking or embedding strategies degrade performance
- Latency overhead: Vector search and document retrieval add inference time
- Doesn’t change model behavior: Can’t teach new reasoning patterns or stylistic preferences
- Struggles with synthesis: Combining information across many documents can be challenging
Understanding Fine-Tuning
How Fine-Tuning Works
Fine-tuning modifies the model’s weights through additional training on domain-specific data. Unlike RAG, fine-tuning changes the model itself, teaching it new patterns, behaviors, or knowledge.
The process typically involves:
- Dataset preparation: Create high-quality training examples (prompt-completion pairs)
- Base model selection: Choose appropriate foundation model for fine-tuning
- Training configuration: Set learning rates, batch sizes, and epochs
- Fine-tuning execution: Update model weights using your dataset
- Evaluation and iteration: Test performance and refine as needed
- Deployment: Host the fine-tuned model for inference
Fine-Tuning Approaches
Several fine-tuning methodologies have emerged:
- Full fine-tuning: Update all model parameters (expensive, highest customization)
- LoRA (Low-Rank Adaptation): Update a small number of additional parameters (cost-efficient)
- Adapter layers: Add small trainable modules between frozen layers
- Prompt tuning: Learn optimal prompt embeddings rather than modifying model weights
Fine-Tuning in Production: Credit Risk Assessment
Our financial services client needed LLMs to analyze unstructured financial documents (business plans, market analyses, management discussions) for commercial loan underwriting. While GPT-4 could extract information, it lacked the financial institution’s proprietary risk assessment framework.
We combined RAG with fine-tuning:
- RAG component: Retrieved relevant sections from financial documents
- Fine-tuned GPT-3.5-turbo: Trained on 5,000+ historical underwriting decisions to learn the institution’s risk assessment patterns
- Ensemble approach: Combined fine-tuned LLM analysis with traditional credit scoring models
Why fine-tuning in addition to RAG?
- Proprietary methodology: The institution’s risk framework wasn’t easily captured in retrievable documents
- Consistent evaluation criteria: Fine-tuning ensured uniform application of risk factors
- Nuanced judgment: The model learned subtle patterns in how experienced underwriters weighed different risk signals
The result: 40% reduction in underwriting time with 25% improvement in risk prediction accuracy.
Fine-Tuning Strengths
- Behavioral consistency: Model learns specific reasoning patterns and stylistic preferences
- Task-specific optimization: Can significantly improve performance on narrow, well-defined tasks
- No retrieval overhead: Knowledge is encoded in model weights, no vector search required
- Learns from patterns: Can capture nuanced relationships that aren’t explicit in documents
- Smaller, specialized models: Can create efficient models for specific use cases
Fine-Tuning Limitations
- High computational cost: Requires GPU resources and training time
- Data requirements: Needs hundreds to thousands of high-quality training examples
- Knowledge staleness: Updates require retraining the entire model
- Catastrophic forgetting: Can degrade general capabilities while learning domain-specific knowledge
- Difficult debugging: Hard to understand why model behavior changed
- Version management complexity: Must maintain and deploy custom model versions
Decision Framework:
RAG vs Fine-Tuning
Choose RAG When:
1. Knowledge Frequently Updates
The sales enablement RAG system we built for a technology company manages 800+ product documents that update monthly. Fine-tuning would require monthly model retraining which is both prohibitively expensive and operationally complex. RAG allows immediate knowledge updates by simply re-indexing modified documents.
2. Transparency and Citations Are Critical
Healthcare, legal, and regulatory applications require verifiable information sources. The medical knowledge assistant provides citations for every claim, allowing patients to verify information against peer-reviewed research. Fine-tuned models can’t provide this transparency—knowledge is encoded in inscrutable weights.
3. Domain Knowledge Is Explicit
If your expertise exists in documents, databases, or structured knowledge bases, RAG can effectively leverage it. The government document classification system retrieved from 2.5 million legacy documents, knowledge that couldn’t practically be encoded through fine-tuning.
4. Data Privacy and Compliance Matter
HIPAA, GDPR, and other regulations often restrict encoding sensitive data in model weights. RAG keeps data in compliant storage systems with proper access controls, encryption, and audit trails.
5. Budget Is Constrained
RAG requires no model training-only embedding generation and vector storage. For most organizations, this represents significantly lower cost than fine-tuning infrastructure.
Choose Fine-Tuning When:
1. You Need Consistent Task Performance
The credit risk assessment system benefited from fine-tuning because it needed to apply the same evaluation criteria consistently across thousands of loan applications. Fine-tuning embedded the institution’s risk methodology directly into model behavior.
2. Knowledge Is Implicit or Behavioral
Some expertise isn’t easily captured in documents, it’s embodied in how experts approach problems, weigh trade-offs, or communicate. Fine-tuning can learn these patterns from examples of expert behavior.
3. You Have High-Quality Training Data
If you have thousands of examples of desired model behavior (e.g., historical customer service interactions, past underwriting decisions, expert annotations), fine-tuning can learn from these patterns.
4. Inference Latency Is Critical
RAG adds retrieval overhead to every request. Applications requiring sub-100ms response times may benefit from fine-tuned models that encode knowledge in weights rather than retrieving it dynamically.
5. You Need Specialized Model Behavior
Fine-tuning excels at teaching models specific output formats, reasoning patterns, or stylistic preferences that are difficult to achieve through prompting alone.
Combine Both When:
Complex Enterprise Applications
The most sophisticated systems we’ve deployed combine RAG and fine-tuning:
- Fine-tune for task behavior: Teach the model how to approach the problem
- RAG for knowledge retrieval: Provide current, verifiable information
- Ensemble with traditional ML: Combine LLM insights with proven statistical models
The credit risk system exemplifies this approach: fine-tuned GPT-3.5-turbo learned risk assessment methodology, RAG retrieved relevant financial documents, and XGBoost models provided traditional credit scoring, with each component addressing different aspects of the underwriting challenge.
Implementation Considerations
RAG Implementation Challenges
Chunking Strategy
Poor chunking destroys retrieval quality. The medical knowledge assistant required custom chunking logic that:
- Preserved medical context across chunk boundaries
- Maintained relationships between symptoms, diagnoses, and treatments
- Handled tables, lists, and structured clinical data
- Optimized chunk size (250-500 tokens) based on empirical testing
Embedding Model Selection
General-purpose embeddings (OpenAI ada-002, sentence-transformers) work well for many domains. However, specialized embeddings often significantly improve retrieval:
- BioBERT for medical/healthcare applications
- FinBERT for financial document analysis
- Legal-BERT for legal document retrieval
- CodeBERT for software documentation
The healthcare RAG system improved retrieval accuracy by 35% when switching from general embeddings to BioBERT.
Retrieval Optimization
Simple vector similarity often isn’t sufficient:
- Hybrid search: Combine vector similarity with keyword matching
- Re-ranking: Use a second model to re-score retrieved candidates
- Query expansion: Generate multiple query variations to improve recall
- Metadata filtering: Pre-filter by date, category, or other attributes before vector search
Fine-Tuning Implementation Challenges
Dataset Quality
Fine-tuning performance depends entirely on training data quality. The credit risk model required:
- 5,000+ historical underwriting decisions
- Expert review of training examples for accuracy
- Balanced representation of different risk profiles
- Consistent annotation standards
Poor quality training data leads to poor model performance—there’s no way around this fundamental constraint.
Preventing Catastrophic Forgetting
Fine-tuning can degrade a model’s general capabilities while teaching domain-specific knowledge. Mitigation strategies include:
- Including general examples in training data
- Using LoRA instead of full fine-tuning
- Careful learning rate tuning
- Regular evaluation on general benchmarks during training
Model Serving Infrastructure
Unlike RAG (which uses existing API endpoints), fine-tuned models require custom deployment infrastructure:
- GPU-enabled inference servers
- Model versioning and rollback capabilities
- A/B testing infrastructure for comparing model versions
- Monitoring for model drift and performance degradation
Cost Comparison
RAG Costs
- Embedding generation: One-time cost for initial corpus, incremental for updates
- Vector database: Storage and query costs (typically $50-500/month depending on scale)
- LLM inference: Per-token costs for prompt + retrieved context + completion
- Maintenance: Engineering time for improving retrieval quality
The sales enablement RAG system costs approximately $800/month for 10,000 queries (Azure OpenAI GPT-4, Azure AI Search).
Fine-Tuning Costs
- Dataset preparation: Labor-intensive: $10,000-50,000 for quality datasets
- Training compute: GPU hours: $500-5,000 per training run
- Inference infrastructure: GPU-enabled servers: $500-5,000/month
- Model updates: Retraining costs each time knowledge needs updating
The fine-tuned credit risk model cost $25,000 for initial dataset preparation and training, plus $1,200/month for inference infrastructure.
TCO Considerations
For most enterprise applications, RAG offers superior total cost of ownership:
- Lower upfront investment
- No specialized infrastructure required
- Easier maintenance and updates
- More transparent debugging and optimization
Fine-tuning makes economic sense when:
- You have significant query volume (100,000+ per month)
- Inference latency directly impacts revenue
- You already have high-quality training data
- The fine-tuned model can serve multiple use cases
Hybrid Architectures:
The Future of Enterprise AI
The most effective enterprise AI systems we’ve deployed combine multiple approaches:
Architecture Pattern: Retail Inventory Orchestration
The multi-agent retail system used:
- Fine-tuned demand forecasting: Learned seasonal patterns and local market dynamics
- RAG for supplier coordination: Retrieved current lead times, pricing, and contract terms
- Traditional ML for inventory optimization: XGBoost models for stock level recommendations
- LangGraph orchestration: Coordinated multi-agent decision-making
This hybrid approach delivered 28% reduction in carrying costs and 15% improvement in stock availability, better than any single technique could achieve.
Practical Recommendations
For Most Organizations: Start With RAG
RAG offers the best risk-adjusted return for most enterprise AI applications:
- Lower upfront investment
- Faster time to production
- Easier iteration and improvement
- Better transparency and debugging
- Lower ongoing costs
The medical knowledge assistant, sales enablement platform, and government classification system all achieved their objectives with RAG alone.
Consider Fine-Tuning When RAG Isn’t Sufficient
Add fine-tuning to your architecture when:
- You need consistent task-specific behavior that prompting can’t achieve
- You have high-quality training data representing desired model behavior
- Inference latency requirements preclude retrieval overhead
- You can justify the higher development and operational costs
Think Hybrid From the Start
Design your architecture to support both approaches:
- Build RAG infrastructure first
- Collect production data for potential fine-tuning
- Measure performance gaps that RAG can’t close
- Add fine-tuning selectively where it provides clear ROI
Conclusion
RAG and fine-tuning aren’t competing alternatives. They’re complementary techniques that address different aspects of LLM customization:
- RAG excels at dynamic knowledge retrieval: providing current, verifiable information from external sources
- Fine-tuning excels at behavioral consistency: teaching models specific reasoning patterns and task performance
- Hybrid approaches combine the strengths of both while mitigating their individual limitations
The production deployments examined in this article-spanning healthcare, sales, finance, retail, and government demonstrate that successful enterprise AI requires thoughtful architectural decisions based on specific business requirements, data availability, compliance constraints, and cost considerations.
For most organizations, the optimal path is:
- Start with RAG for knowledge retrieval and transparency
- Measure performance against business objectives
- Add fine-tuning selectively where behavioral consistency justifies the cost
- Continuously optimize based on production performance data
The organizations that succeed with enterprise AI in 2025 will be those that choose the right techniques for the right problems—not those that blindly follow trends or apply one-size-fits-all solutions.