


The Production Gap
Building an AI model that works in development is fundamentally different from deploying a system that operates reliably in production. The gap between these two states has derailed countless AI initiatives:
- A healthcare AI delivers impressive accuracy in testing but violates HIPAA compliance in production
- A financial risk model performs well initially but degrades silently as market conditions shift
- A retail forecasting system can’t explain why its predictions suddenly changed, eroding business trust
- A government classification system lacks the audit trails required for regulatory oversight
The difference between prototype and production isn’t just scale, it’s operational maturity. This article examines the MLOps practices that bridge this gap, drawing from real deployments across regulated industries.
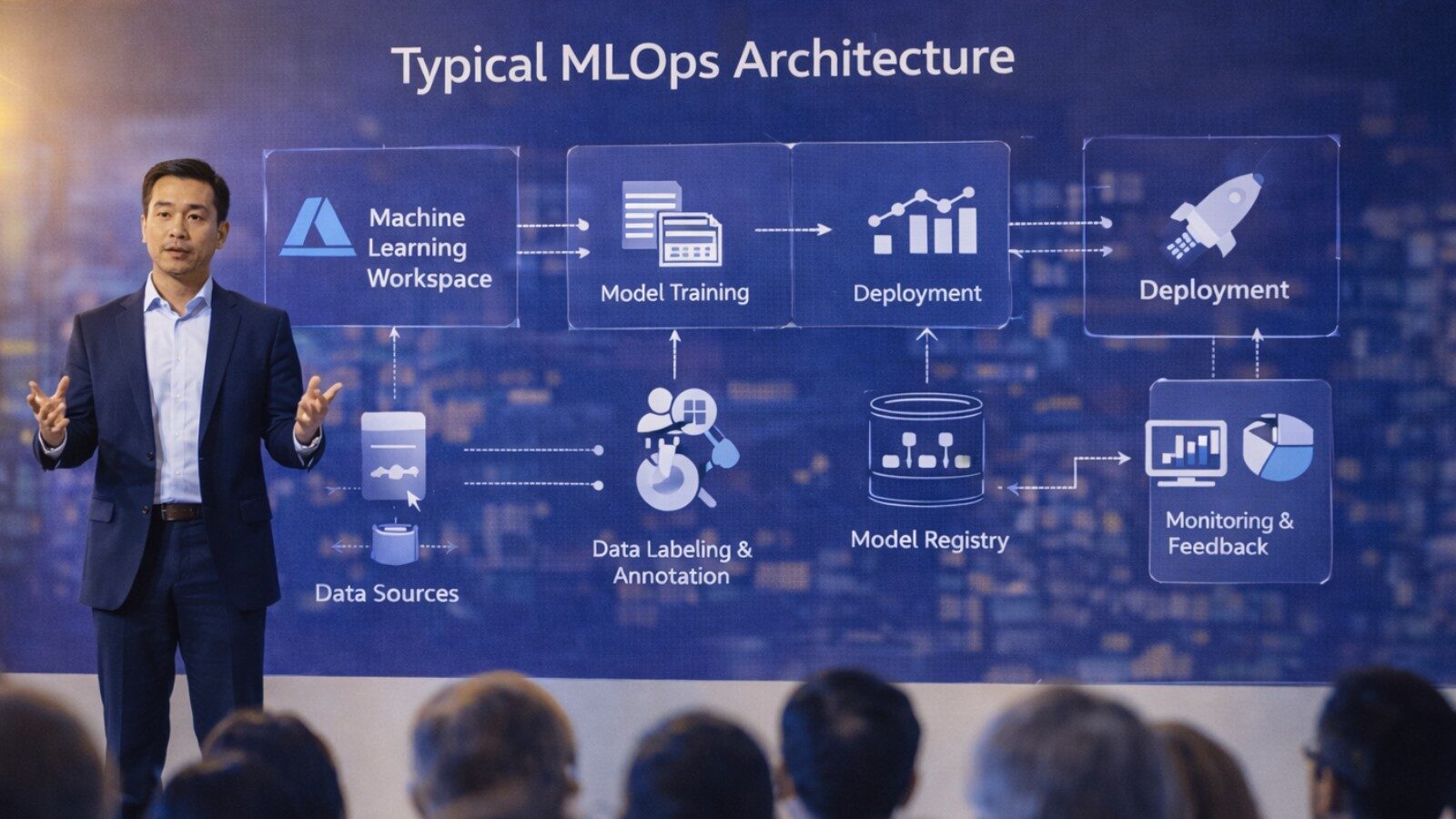
The MLOps Framework
MLOps extends DevOps principles to machine learning systems, addressing challenges unique to AI deployments:
Core MLOps Components
- Model versioning and registry: Track model lineage, parameters, and performance
- Automated training pipelines: Reproduce model training reliably
- Continuous monitoring: Detect performance degradation and drift
- A/B testing infrastructure: Validate improvements before full deployment
- Compliance and auditing: Document decisions for regulatory requirements
- Incident response: Quickly diagnose and resolve production issues
- Feedback loops: Incorporate production data to improve models
Let’s examine how these components manifest in production AI systems.
Case Study:
Healthcare MLOps & HIPAA Compliance at Scale
The Challenge
Our HIPAA-compliant medical knowledge assistant faced operational requirements that development testing couldn’t reveal:
- Every patient interaction required audit trails for compliance
- Model predictions needed to be reproducible for medical review
- Performance degradation could impact patient safety
- Updates required validation against clinical accuracy standards
MLOps Implementation
1. Compliance-First Architecture
We built compliance into every layer:
- Azure Private Endpoints: All AI services accessed through private networking
- Audit logging: Every query, retrieval, and response logged with timestamps and user context
- Data lineage tracking: Document provenance from source to patient-facing response
- Access controls: Role-based permissions with principle of least privilege
- Encryption: At rest and in transit, using FIPS 140-2 compliant algorithms
2. Model Versioning
Every component received semantic versioning:
- Embedding model: BioBERT version tracked in model registry
- Chunking logic: Version controlled with Git, tagged for each deployment
- LLM version: GPT-4 API version pinned to ensure reproducibility
- Retrieval parameters: Top-k, similarity thresholds, re-ranking weights documented
- Prompt templates: Versioned and tested before production deployment
3. Continuous Monitoring
We monitored multiple dimensions:
Performance Metrics:
- Query latency (p50, p95, p99)
- Retrieval relevance scores
- LLM token consumption
- Error rates by category
Clinical Quality Metrics:
- Medical accuracy (reviewed by physicians)
- Citation quality (source document relevance)
- Response completeness
- Patient comprehension (readability scores)
Business Metrics:
- Patient engagement rates
- Consultation volume reduction
- Physician time savings
- Patient satisfaction scores
4. Feedback Loops
Physicians reviewed a random sample of 5% of responses weekly. Low-confidence predictions were automatically flagged for review. This feedback drove continuous improvement:
- Identified gaps in knowledge base coverage
- Refined chunking strategies for complex medical topics
- Improved prompt engineering for clarity
- Updated retrieval parameters based on relevance patterns
Operational Impact
The MLOps infrastructure enabled:
- 100% audit compliance: Complete documentation for every patient interaction
- Zero downtime deployments: Blue-green deployment with instant rollback
- 5-minute incident detection: Automated alerts for performance degradation
- Continuous accuracy improvement: Weekly model refinements based on physician feedback
Case Study:
Financial Services MLOps & Model Drift and Retraining
The Challenge
Our credit risk assessment system combined fine-tuned LLMs with traditional ML models. Financial markets change continuously—model performance that’s excellent today may be inadequate tomorrow. The challenge: detect degradation early and retrain efficiently.
MLOps Implementation
1. Multi-Model Pipeline Orchestration
We used Azure Machine Learning to orchestrate the ensemble:
- Document processing pipeline: OCR, table extraction, text normalization
- LLM analysis: Fine-tuned GPT-3.5-turbo for document insights
- Feature engineering: Combining LLM outputs with structured credit data
- XGBoost scoring: Traditional risk model with LLM-derived features
- Ensemble logic: Weighted combination of multiple signals
Each component versioned independently, allowing targeted updates without full system retraining.
2. Drift Detection
We monitored multiple drift types:
Data Drift:
- Statistical distribution changes in input documents
- New document types or formats not seen during training
- Vocabulary drift in business plan language
Concept Drift:
- Changing relationships between features and credit risk
- Market condition shifts affecting default rates
- Regulatory changes impacting risk assessment criteria
Performance Drift:
- Declining accuracy on hold-out test sets
- Increasing divergence between predicted and actual outcomes
- Rising underwriter override rates
3. Automated Retraining Pipeline
Drift detection triggered automated retraining:
- Alert Generation: Significant drift triggers retraining workflow
- Data Collection: Gather recent loan applications and outcomes
- Dataset Preparation: Combine with historical data, balance classes
- Model Training: Retrain affected components (LLM, XGBoost, or both)
- Validation: Test against hold-out set and business validation criteria
- Shadow Deployment: Run new model alongside production model
- A/B Testing: Gradual rollout with performance comparison
- Full Deployment: Replace production model if A/B test succeeds
4. Model Registry and Governance
Every model version tracked:
- Training dataset version and statistics
- Hyperparameters and training configuration
- Validation metrics and business KPIs
- Deployment history and rollback points
- Compliance documentation and approval workflows
Operational Impact
- 3 automated retraining cycles in first 5 months, maintaining accuracy as market conditions shifted
- Zero model-related compliance violations: complete audit trails for regulatory review
- 15-minute rollback capability: instant reversion if new model underperforms
- 25% improvement in risk prediction through continuous model refinement
Case Study:
Retail MLOps & Multi-Agent System Coordination
The Challenge
Our retail inventory optimization system used LangGraph to orchestrate multiple specialized agents. The operational challenge: monitor and debug a system where decisions emerge from agent interactions rather than deterministic code paths.
MLOps Implementation
1. Agent Observability
We instrumented every agent interaction:
- Agent execution traces: Complete decision path for every inventory action
- Inter-agent messages: Communication logs between demand forecasting, supplier coordination, and rebalancing agents
- Decision rationale: LLM explanations for each recommendation
- Performance attribution: Which agent contributed to business outcomes
2. Simulation and Testing
Before deploying agent updates to production:
- Historical replay: Run new agent versions against past scenarios
- Synthetic scenario testing: Evaluate behavior under extreme conditions (supply shortages, demand spikes)
- Business rule validation: Ensure agent decisions respect hard constraints (budget limits, storage capacity)
3. Continuous Evaluation
Agent performance assessed daily:
- Demand forecast accuracy: Predicted vs actual sales by location and product
- Supplier negotiation effectiveness: Cost savings vs baseline pricing
- Inventory optimization: Stockout rates, carrying costs, turnover ratios
- System-level KPIs: Overall business impact of agent decisions
4. Human-in-the-Loop Safeguards
Critical decisions required human approval:
- Large purchase orders (>$50K) flagged for manager review
- Significant inventory transfers between locations
- Deviations from seasonal forecasting patterns
- New supplier selections
Operational Impact
- Complete decision auditability: Every inventory action traceable to specific agent reasoning
- Rapid debugging: Agent execution traces enabled quick diagnosis of unexpected behavior
- Safe experimentation: Simulation environment allowed testing new agent strategies without production risk
- 28% cost reduction through continuous agent optimization based on performance feedback
Case Study:
Government MLOps & Compliance and Reproducibility
The Challenge
Our government document classification system faced the strictest operational requirements:
- IL5 security compliance for all components
- Complete reproducibility for any classification decision
- Human review workflows with detailed audit trails
- NIST 800-171 controls for all data handling
MLOps Implementation
1. Immutable Model Artifacts
Every model component stored in immutable registry:
- Model weights: Checksummed and versioned
- Training data: Hashed with cryptographic verification
- Inference code: Git SHA pinned to specific commits
- Dependencies: Containerized with reproducible builds
- Configuration: Environment variables and parameters versioned
2. Classification Audit Trails
Every document classification captured:
- Document identifier and metadata
- Model version used for classification
- Confidence scores for all candidate classes
- Active learning decision (auto-approve vs human review)
- Human reviewer identity (if applicable)
- Final classification and rationale
- Timestamp and system state
3. Security-First Operations
- Azure Government Cloud: IL5-compliant infrastructure
- Network isolation: No internet egress, private endpoints only
- Access logging: Every system access logged and monitored
- Encryption: FIPS 140-2 compliant cryptography throughout
- Continuous compliance scanning: Automated NIST 800-171 validation
4. Active Learning Pipeline
Human-in-the-loop workflow optimized for accuracy and efficiency:
- GPT-4 classifies document with confidence score
- High-confidence predictions (>95%) auto-approved
- Low-confidence predictions routed to human reviewers
- Human feedback incorporated into training data
- Weekly model retraining with expanded dataset
- Continuous accuracy improvement tracked
Operational Impact
- 100% audit compliance: Complete documentation for regulatory oversight
- Perfect reproducibility: Any classification decision reproducible months later
- Zero security violations: Continuous compliance monitoring
- 97.3% accuracy achieved through active learning and human feedback
- 75% cost reduction vs fully manual classification
MLOps Best Practices:
Synthesis
1. Build Observability From Day One
Every successful deployment prioritized observability early:
- Comprehensive logging: Inputs, outputs, intermediate states, errors
- Performance metrics: Latency, throughput, resource utilization
- Business metrics: KPIs that matter to stakeholders
- Quality metrics: Accuracy, relevance, user satisfaction
Systems without observability become black boxes when problems arise. Debugging production issues without logs is prohibitively expensive.
2. Version Everything
Model reproducibility requires versioning all components:
- Model weights and architectures
- Training and validation datasets
- Training code and hyperparameters
- Inference code and dependencies
- Configuration and environment variables
- Prompt templates and retrieval parameters
The credit risk system’s ability to quickly rollback degraded models depended on comprehensive versioning.
3. Automate Testing and Validation
Manual testing doesn’t scale. Successful deployments automated:
- Unit tests: Component-level functionality
- Integration tests: End-to-end system behavior
- Performance tests: Latency and throughput benchmarks
- Regression tests: Ensure updates don’t break existing functionality
- Business validation: Domain-specific quality checks
The retail system’s simulation environment exemplifies this—new agent strategies tested against historical scenarios before production deployment.
4. Plan for Model Drift
All models degrade over time. Production systems need:
- Drift detection: Automated monitoring for data, concept, and performance drift
- Retraining pipelines: Automated workflows for model updates
- Validation infrastructure: Rigorous testing before deployment
- Rollback capabilities: Quick reversion if updates underperform
The financial services system’s automated retraining maintained accuracy as market conditions shifted.
5. Design for Compliance
Regulatory requirements shape architecture:
- Audit trails: Complete decision documentation
- Reproducibility: Ability to recreate any prediction
- Access controls: Role-based permissions and least privilege
- Data handling: Encryption, retention policies, privacy controls
- Continuous validation: Automated compliance scanning
Healthcare and government deployments demonstrated that compliance can’t be retrofitted—it must be architectural from the start.
6. Implement Gradual Rollouts
Never deploy updates to 100% of traffic immediately:
- Shadow deployment: Run new model alongside production without impacting users
- Canary releases: Deploy to small percentage of traffic first
- A/B testing: Compare new vs old model performance
- Progressive rollout: Gradually increase traffic to new model
- Instant rollback: Revert to previous version if issues arise
7. Close the Feedback Loop
Production data is your most valuable training resource:
- User feedback collection: Explicit ratings and implicit signals
- Error analysis: Understand failure modes
- Edge case identification: Find scenarios not covered in training
- Continuous improvement: Regular model updates based on production learnings
The medical assistant’s physician review process and the government system’s active learning both exemplify effective feedback loops.
8. Balance Automation and Human Oversight
Critical decisions require human judgment:
- High-stakes predictions: Medical diagnoses, credit decisions, security classifications
- Low-confidence outputs: When model uncertainty is high
- Novel scenarios: Situations not represented in training data
- Regulatory requirements: Where human approval is mandated
Human-in-the-loop workflows provide the right balance between automation efficiency and decision quality.
MLOps Tooling Landscape
Model Development and Training
- Azure Machine Learning: End-to-end ML platform with enterprise features (used in credit risk system)
- Databricks: Unified analytics platform with MLflow integration
- Kubeflow: Kubernetes-native ML workflows
- Weights & Biases: Experiment tracking and model versioning
Model Serving and Deployment
- Azure OpenAI Service: Managed LLM deployment (used across all case studies)
- TensorFlow Serving: Production ML model serving
- Triton Inference Server: Multi-framework model serving
- Docker + Kubernetes: Containerized deployment (retail system)
Monitoring and Observability
- Azure Monitor: Cloud-native monitoring and alerting
- Prometheus + Grafana: Metrics collection and visualization
- ELK Stack: Log aggregation and analysis
- Arize AI: Specialized ML observability
Data and Feature Management
- Azure AI Search: Vector database with hybrid search (healthcare, sales systems)
- Pinecone: Purpose-built vector database
- Feast: Feature store for ML
- Delta Lake: Reliable data lake storage
Common MLOps Pitfalls
1. Insufficient Testing Before Deployment
Symptom: Model performs well in development but fails in production.
Root Cause: Training data doesn’t match production data distribution.
Solution: Comprehensive testing including edge cases, performance benchmarks, and production-like data.
2. Lack of Monitoring
Symptom: Performance degradation goes unnoticed for weeks or months.
Root Cause: No automated alerts for drift or accuracy decline.
Solution: Comprehensive monitoring with automated alerting thresholds.
3. No Rollback Plan
Symptom: Problematic model update causes hours of downtime.
Root Cause: No mechanism to quickly revert to previous version.
Solution: Blue-green deployments with instant rollback capability.
4. Inadequate Compliance Documentation
Symptom: Regulatory audit reveals missing documentation.
Root Cause: Compliance treated as afterthought rather than architectural requirement.
Solution: Build audit trails and documentation into system from day one.
5. Manual Processes That Don’t Scale
Symptom: Model updates require days of manual work.
Root Cause: No automated pipelines for retraining, validation, and deployment.
Solution: Invest in automation infrastructure early.
Measuring MLOps Maturity
Level 0: Manual Process
- Manual model training and deployment
- No version control
- No automated testing
- No monitoring
Level 1: Automated Training
- Reproducible model training
- Basic version control
- Manual deployment
- Basic monitoring
Level 2: Automated Deployment
- Automated training pipelines
- Comprehensive versioning
- Automated testing and validation
- Continuous monitoring with alerting
- Manual retraining triggers
Level 3: Continuous Learning
- Automated drift detection
- Automated retraining pipelines
- A/B testing infrastructure
- Comprehensive observability
- Production feedback loops
- Compliance automation
The systems described in this article operate at Level 3: continuous learning with automated monitoring, retraining, and deployment.
Conclusion
Production AI requires operational discipline that extends far beyond model development. The deployments examined in this article, spanning healthcare, finance, retail, and government, succeeded because they treated MLOps as a first-class architectural concern, not an operational afterthought.
Key takeaways for enterprise AI leaders:
- Observability is non-negotiable: Systems without comprehensive logging and monitoring become black boxes when problems arise
- Compliance shapes architecture: Regulatory requirements must inform design decisions from day one
- Automation enables scale: Manual processes that work for one model fail for ten
- Model drift is inevitable: Plan for continuous monitoring and retraining
- Human oversight remains critical: Full automation isn’t appropriate for high-stakes decisions
- Gradual rollouts reduce risk: Shadow deployments and A/B testing catch issues before they impact all users
- Feedback loops drive improvement: Production data is your most valuable training resource
The organizations that succeed with AI in 2025 won’t be those with the most sophisticated models, they’ll be those with the operational maturity to deploy, monitor, and continuously improve AI systems at scale. MLOps isn’t optional infrastructure, it’s the foundation that determines whether your AI delivers lasting business value or becomes an operational liability.
Start building your MLOps capabilities today. The gap between prototype and production is where most AI initiatives fail. Close that gap with rigorous operational practices, and you’ll position your organization to realize AI’s transformative potential.